|
Business Forecasting Methods and Techniques |
Single & Multiple Moving Averages
Single & Multiple-Parameters Exponential Smoothing
Exponential Smoothing with Seasonality Methods
Simple and Multiple Regression Analysis
Box-Jenkins (ARIMA) Models
Multivariate Data Analysis
Descriptive Statistics Analysis
Quantitative forecasts are based on data, or observations. A single observation or actual value can be represented by a variable, Xi ,for example, actual sales $ booked. The objective of forecasting then is to predict the future value of X. Individual forecasts can be denoted by variable Fi ,and the error denoted by ei which is the difference between actual and forecast value for observation i, for example:
ei = Xi - Fi . In both time-series and casual forecasting, the variable time interval t denotes the present time period, t - 1 last period, t - 2 two periods ago, and so on. Forecasts are for time periods t + 1, t + 2 ... t + m. For the rest of these sections, I will use the following notations.
|
|
Observed |
Historical |
Present |
Forecasted |
| Values | X1, X2 ... Xn | Xt - n ... Xt - 2, Xt - 1 | Xt | Ft + 1 Ft + 2 ... Ft + m |
| Period i | 1, 2 ... 4 | t - m ... t - 2, t - 1 | t | t + 1, t + 2 ... t + m |
| Estimated values | F1, F2 ... Fn | F - n ... F - 2, F - 1 | Ft | |
| Error | e1, e2 ... en | et - n ...et - 2, et - 1 | et |
Univariate data analysis explores each variable in a data set, separately. It looks at the range of values, as well as the central tendency of the values. It describes the pattern of response to the variable. It describes each variable on its own. Descriptive statistics describe and summarize data. Both Univariate and Bivariate descriptive statistics describe individual variables for the central tendency, variability or dispersion, and shape of the overall distribution.
Bivariate descriptive statistics (e.g., ANOVA, t-tests) often involve more than one quantitative variable being collected and examined. For example, data collected from customers contains kg, feet, locations, dollars spend/week, Return Memo/week. summarizing such data in a way that is analogous to summarizing univariate (single variable) data.
Multivariate
descriptive statistics refers to any statistical technique used to analyze data that arises from more than one variable at a time. Multivariate data analysis is about separating the signal from the noise in data with many variables and presenting the results as easily interpretable plots summarizing the essential information. This essentially models reality where each situation, product, or decision involves more than a single variable. A wide range of methods is used for the analysis of multivariate data such as Regression Analysis, Correspondence Analysis, Factor Analysis, Multidimensional Scaling, and Cluster Analysis.Table 1.1 above contains both univariate and bivariate data set with values in kilogram, and below are their commonly used descriptive statistics.
| Mean, , of volume sold for the past 10 weeks |
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Median (or the middle value) |
= |
=5.5, which is value at the 5.5th position =(4205+4387.9)/2 =4296.45 or, =MEDIAN(B2:B11) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Range |
= |
Max - Min =MAX(B2:B11)-MIN(B2:B11)
=1954.3 kg The range is very sensitive to extreme scores since it is based on only two values. It should almost never be used as the only measure of spread or dispersion, but can be informative if used as a supplement to other measures of spread such as the standard deviation or semi-interquartile range. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Deviation from the Mean |
Xi - |
Note: sum of the deviations always equal to zero, so they should be squared. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Mean Absolute Deviations (MAD) |
MAD = |
=SUMPRODUCT(ABS(D2:D11))/COUNT(A2:A11) =494.63 kg |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Sum of Squared Deviations (SSD) |
SSD = |
=3,467,309.86 kg |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Mean Squared Deviation (MSD) |
MSD = |
=346,730.98 kg. It is also called the Maximum Likelihood Estimate (MLE). |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Variance, var (x) or S2, is the sum of squared deviations divided by the degrees of freedom |
S2 = |
=SUM(E2:E11)/(COUNT(A2:A11)-1) =385,256.65 kg |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
The degrees of freedom (df)
can be defined as the number of data points minus the number of
parameters estimated (which is 1 in the data kilograms) S2 is closely related to MSD, and because it has a smaller denominator, its value is always larger than MSD. Variance S2 is an unbiased estimator of this sample sales variance, whereas MSD is a biased estimator of the sample data variance. (If the mean value of an estimator equals the true value of the quantity it estimates, the estimator is called an unbiased estimator. An estimator is a biased estimator if its expected value is not equal to the value of the population parameter being estimated). The variance, standard deviation, standard error, as well as the range, all are measuring variability. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Covariance, Covxy | cov(x,F) = |
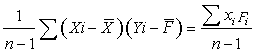
=3506987.60 / 9 =389665.29 kg-feet |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Covariance is the measure of how
much two variables change together. The covariance becomes more
positive for each pair of values which differ from their mean in
the same direction. The covariance becomes more negative with
each pair of values which differ from their mean in opposite
directions (in another word, if one of them tends to be above
its expected value when the other variable is below its
expected value. (Variance is a special case of the
Covariance when the two variables are identical).
Note that the units of covariance, kg-feet, is difficult to interpret. Hence we want to compute the correlation coefficient from Pearson's r which takes care of this scaling problem as described below. If Covariance is divided by the two standard deviations, then the units in the numerator and denominator cancel, leaving with dimensionless number, which will be Pearson's r, the Correlation Coefficient as shown below. Dividing the covariance by the two standard deviations restricts the range r to the interval -1 to +1.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Pearson's correlation is symmetric in the sense that the correlation of X with Y is the same as the correlation of Y with X. A critical property of Pearson's r is that it is unaffected by linear transformations - which means that multiplying a variable by a constant and/or adding a constant does not change the correlation of that variable with other variables. If Y is the transformed value of X, then Y = mX + b.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Pearson's Correlation Coefficient, r |
r |
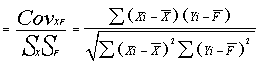
=SUMPRODUCT((D2:D11),(G2:G11))/SQRT(E12*H12) =3506987.6 / 3709628.2 =0.945 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Root Mean Square (RMS) |
RMS = |
=SQRT(SUM(E2:E11)/COUNT(A2:A11)) =588.84 kg |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Standard Deviation (SD) denoted by σ |
|
=SQRT(SUM(E2:E11)/(COUNT(A2:A11)-1)) =620.69 kg. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Standard Deviation is a measure of the variability or dispersion of a population or a data set. A low standard deviation indicates that the data points tend to be very close to the the mean, while high standard deviation means the data are spread out over a large range of values. It is also commonly used to measure confidence in statistical conclusions | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Standard Error of the Mean (SEM) |
|
=STDEV(B2:B11)/SQRT(COUNT(B2:B11)) or, STDEV(B2:B11)/(10^(1/2)) =196.280 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SEM is the standard deviation of the error in the sample mean relative to the true mean, since the sample mean is an "unbiased estimator". It is also the standard deviation of the sample mean estimate of a population mean. The standard error of the mean is a "biased estimator" of the population standard error. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Coefficient of Variation (CV)
|
CVX
=
|
=(620.69/4310.53)*100 =14.399
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| This coefficient provides a unitless measure of the variation of the distribution, by translating it into a percentage of the mean value. This CV value can be used when comparing two parameter samples that have different means and standard deviations. When the mean is close to 0, the CV value becomes of little use. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Skewness |
|
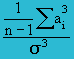
= SUMPRODUCT((D2:D11)^3)/(COUNT(D2:D11)-1)*(SQRT(SUM(E2:E11)/(COUNT(E2:E11)-1))^3) = (-386035317.05) / 9*(620.69)3 = −0.179
Excel, however, uses a slightly different
equation for skewness, as shown below. Using Excel's Data
Analysis Tool, I obtain the value
−0.224. The two results are pretty close. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
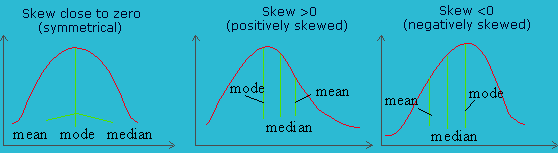
On the right, the positively skewed distribution curve rises rapidly, reaches the maximum and falls slowly; and the tail as well as median on the right-hand side. A negatively skewed distribution curve rises slowly, reaches its maximum and falls rapidly, and the tail as well as the median are on the left-hand side. |
 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Standard Error of Skewness |
= |
=SQRT(6/10) =0.775 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Measures using Skewness and Kurtosis help to decide normality. Skewness measure indicates the level of non-symmetry. If the distribution of the data are symmetric, then skewness will be close to zero. How can we tell if the skewness is large enough to be a concern? This can be checked using a measure of the standard error of skewness. If the skewness is more than twice this amount, in this case 1.549, then it indicates that the distribution of the data is non-symmetric. However, this does not indicate that the sales data are normally distributed. If Skew is >0, the distribution has a pronounced right tail; whereas if Skew is <0, then the distribution will have a left tail. The sales data distribution shows a negative skewness because the negative deviations dominate the positive deviations, when cubed. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Kurtosis or Kurt(X) |
|
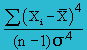
this the Kurtosis formula, but Excel is using a different formula as shown below. 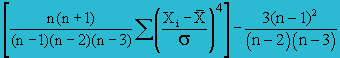 =KURT(B2:B11) = −0.738 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Kurtosis
is a measure of the peakedness and flatness of the data
distribution. Again, for normally distributed data, the kurtosis
is zero. Heavier tailed distributions have larger kurtosis
measures. The normal distribution has a kurtosis of 0
irrespective of its mean or standard deviation. Positive
kurtosis indicates a relatively peaked distribution. Negative
kurtosis indicates a relatively flat distribution. As with skewness, if the value of kurtosis is too big or too small,
there is concern about the normality of the distribution. In
this case, a rough formula for the
Standard Error of Kurtosis is =SQRT(24/N) = 0.1.549.
Twice this amount is 3.099.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Least-Squares Fitting Technique Least-Squares Method is used to find the best-fitting curve to a given set of data, x1...xn by minimizing the sum of the squares of the offsets ("the residuals", also called the Sum of Squared Errors or Deviations, SSD) of the points from the curve. Because the sum of the squares of the offsets is used instead of the offset absolute values, outlying points can have a disproportionate effect on the fit, a property which may or may not be desirable depending on the problem at hand. Least-Squares Method can be linear and non-linear, and categorized further as ordinary least squares (OLS), weighted least squares (WLS), and alternating least squares (ALS). Ordinary Linear Least Squares (LLS) fitting technique is the simplest and most commonly applied form of linear regression and provides a solution to the problem of finding the best fitting straight line through a set of points. Although Excel can plot a trend line instantly for your
graphs, but let's use this LLS method
as an example to understand the logic and calculation of the
coefficients and a
straight line that best fits the historical data in Table 1.2 .The equation for the
line is: y = mx + b Let X be the number of hours that employees clocked in for work in a typical month, Y be the total units of production output recorded, and there were 11 employees' sample data collected for analysis.
Table 1.2 Ordinary Least Square Fitting Method to find the best linear Line fit on the bivariate data
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Mean of total hours worked Mean of the monthly output |
=
= |
SUM(B2:B12)/COUNT($B$2:$B$12)
=250.09 SUM(C2:C12)/COUNT($B$2:$B$12) =23271.55 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
The slope m
|
m =
|
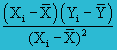
=539981.45 / 8444.91 =63.942 or, use this =INDEX(LINEST(C$2:C$12,B$2:B$12),1)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
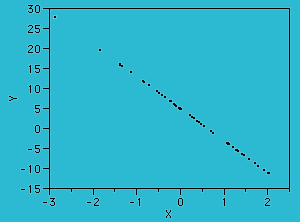
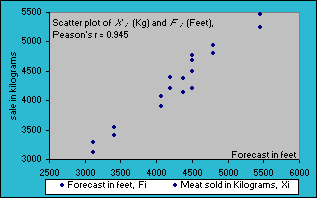
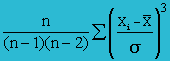
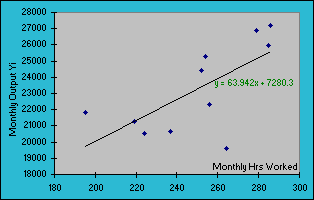
Table 1.3 Single Time Series lagged On Itself To Determine The Auto-Covariance and Auto-Correlation
| A | B | C | D | E | F | G | H | I | J | K | L | M | |
| 1 | t |
|
|
|
|
|
|
|
|
|
|
|
|
| 2 | 1 | 101 | 34.05 | 1159.40 | |||||||||
| 3 | 2 | 40 | 101 | -26.95 | 34.05 | 726.30 | -917.65 | ||||||
| 4 | 3 | 36 | 40 | 101 | -30.95 | -26.95 | 34.05 | 957.90 | 834.10 | -1053.85 | |||
| 5 | 4 | 116 | 36 | 40 | 101 | 49.05 | -30.95 | -26.95 | 34.05 | 2405.90 | -1518.10 | -1321.90 | 1670.15 |
| 6 | 5 | 54 | 116 | 36 | 40 | -12.95 | 49.05 | -30.95 | -26.95 | 167.70 | -635.20 | 400.80 | 349.00 |
| 7 | 6 | 52 | 54 | 116 | 36 | -14.95 | -12.95 | 49.05 | -30.95 | 223.50 | 193.60 | -733.30 | 462.70 |
| 8 | 7 | 93 | 52 | 54 | 116 | 26.05 | -14.95 | -12.95 | 49.05 | 678.60 | -389.45 | -337.35 | 1277.75 |
| 9 | 8 | 33 | 93 | 52 | 54 | -33.95 | 26.05 | -14.95 | -12.95 | 1152.60 | -884.40 | 507.55 | 439.65 |
| 10 | 9 | 77 | 33 | 93 | 52 | 10.05 | -33.95 | 26.05 | -14.95 | 101.00 | -341.20 | 261.80 | -150.25 |
| 11 | 10 | 64 | 77 | 33 | 93 | -2.95 | 10.05 | -33.95 | 26.05 | 8.70 | -29.65 | 100.15 | -76.85 |
| 12 | 11 | 43 | 64 | 77 | 33 | -23.95 | -2.95 | 10.05 | -33.95 | 573.60 | 70.65 | -240.70 | 813.10 |
| 13 | 12 | 59 | 43 | 64 | 77 | -7.95 | -23.95 | -2.95 | 10.05 | 63.20 | 190.40 | 23.45 | -79.90 |
| 14 | 13 | 27 | 59 | 43 | 64 | -39.95 | -7.95 | -23.95 | -2.95 | 1596.00 | 317.60 | 956.80 | 117.85 |
| 15 | 14 | 94 | 27 | 59 | 43 | -27.05 | -39.95 | -7.95 | -23.95 | 731.70 | -1080.65 | -215.05 | -647.85 |
| 16 | 15 | 113 | 94 | 27 | 59 | 46.05 | -27.05 | -39.95 | -7.95 | 2120.60 | 1245.65 | -1839.70 | -366.10 |
| 17 | 16 | 109 | 113 | 94 | 27 | 42.05 | 46.05 | -27.05 | -39.95 | 1768.20 | 1936.40 | 1137.45 | -1679.90 |
| 18 | 17 | 69 | 109 | 113 | 94 | 2.05 | 42.05 | 46.05 | -27.05 | 4.20 | 86.20 | 94.40 | 55.45 |
| 19 | 18 | 39 | 69 | 109 | 113 | -27.95 | 2.05 | 42.05 | 46.05 | 781.20 | -57.30 | -1175.30 | -1287.10 |
| 20 | 19 | 78 | 39 | 69 | 109 | 11.05 | -27.95 | 2.05 | 42.05 | 122.10 | -308.85 | 22.65 | 464.65 |
| 21 | 20 | 42 | 78 | 39 | 69 | -24.95 | 11.05 | -27.95 | 2.05 | 622.50 | -275.70 | 697.35 | -51.15 |
|
sum = |
1339 | 15964.95 | -1563.50 | -2714.71 | 1311.24 | ||||||||
|
mean = |
66.95 | ||||||||||||
| Auto-Cov (lag 1) = -86.86 | Auto-r (lag 1) = - 0.10 | ||||||||||||
| Auto-Cov (lag 2) = - 159.69 | Auto-r (lag 2) = - 0.17 | ||||||||||||
| Auto-Cov (lag 3) = 81.95 | Auto-r (lag 1) = 0.08 | ||||||||||||
Table 1.3 above is a time series of 20 "equally spaced" data points, denoted by t time period. Each individual data element is referred to as Xt. The mean for the series is x-bar. The data is generated randomly. (hint: you can use this formula to generate a series of random numbers, =INT((85-5+1)* RAND()+5); for this case, I used max=85 and min=5). First, I copy a duplicate of this complete time series to column C but offset by a period of one (time lag k=1). Next I do it similarly in column D and E, lagging the time series by a period each until k=3. Column F is the deviation from the mean. Column G, H, I are basically lagging the deviation of the mean in column F by a lag of one period each. Column J is deviation of the mean squared. Column K is multiplying column F by column G, lagging by one period; column L is column F times column H for 2 periods lagging, and column M is column F times column I for a 3 periods lagging. The calculation of autocovariance and autocorrelation, with one-period lag, is using the following equation:
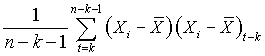
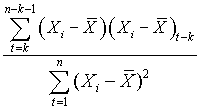
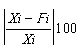
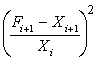
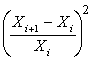
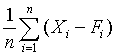
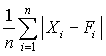
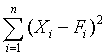
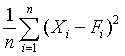
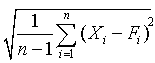
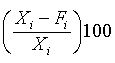
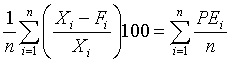
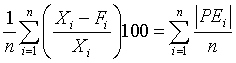
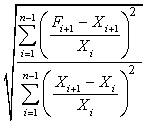
This site
was created in February 2007.
contact Tan, William email:
vbautomation@yahoo.com